import numpy as np
import sympy as sy
sy.init_printing()
import matplotlib.pyplot as plt
plt.style.use("ggplot")np.set_printoptions(precision=3)
np.set_printoptions(suppress=True)def round_expr(expr, num_digits):
return expr.xreplace({n: round(n, num_digits) for n in expr.atoms(sy.Number)})The physical interpretation of determinants is to compute the area enclosed by vectors. For instance, consider the matrix \[ A = \left[\begin{matrix} a & b \\ c & d \end{matrix}\right] \] The determinant represents the area of the parallelogram formed by the vectors \[ \left[\begin{matrix} a \\ c \end{matrix}\right] \quad \text{and} \quad \left[\begin{matrix} b \\ d \end{matrix}\right] \]
Here we demonstrate with a matrix \[ \left[\begin{matrix} 2 & 0\cr 0 & 3 \end{matrix}\right] \] It’s also easy to understand the area formed by these two vectors are actually a rectangle.
matrix = np.array([[2, 0], [0, 3]])
def plot_2ddet(matrix):
# Calculate the determinant of the matrix
det = np.linalg.det(matrix)
# Create a figure and axis
fig, ax = plt.subplots(figsize=(6, 6))
# Plot the vectors
ax.arrow(
0, 0, matrix[0, 0], matrix[0, 1], head_width=0.1, head_length=0.1, color="b"
)
ax.arrow(
0, 0, matrix[1, 0], matrix[1, 1], head_width=0.1, head_length=0.1, color="r"
)
ax.arrow(
matrix[0, 0],
matrix[0, 1],
matrix[1, 0],
matrix[1, 1],
head_width=0.1,
head_length=0.1,
color="r",
)
ax.arrow(
matrix[1, 0],
matrix[1, 1],
matrix[0, 0],
matrix[0, 1],
head_width=0.1,
head_length=0.1,
color="b",
)
# Annotate the determinant value
ax.annotate(f"determinant = {det:.2f}", (matrix[0, 0] / 2, matrix[0, 1] / 2))
# Add labels and show the plot
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.grid()
plt.show()
if __name__ == "__main__":
plot_2ddet(matrix)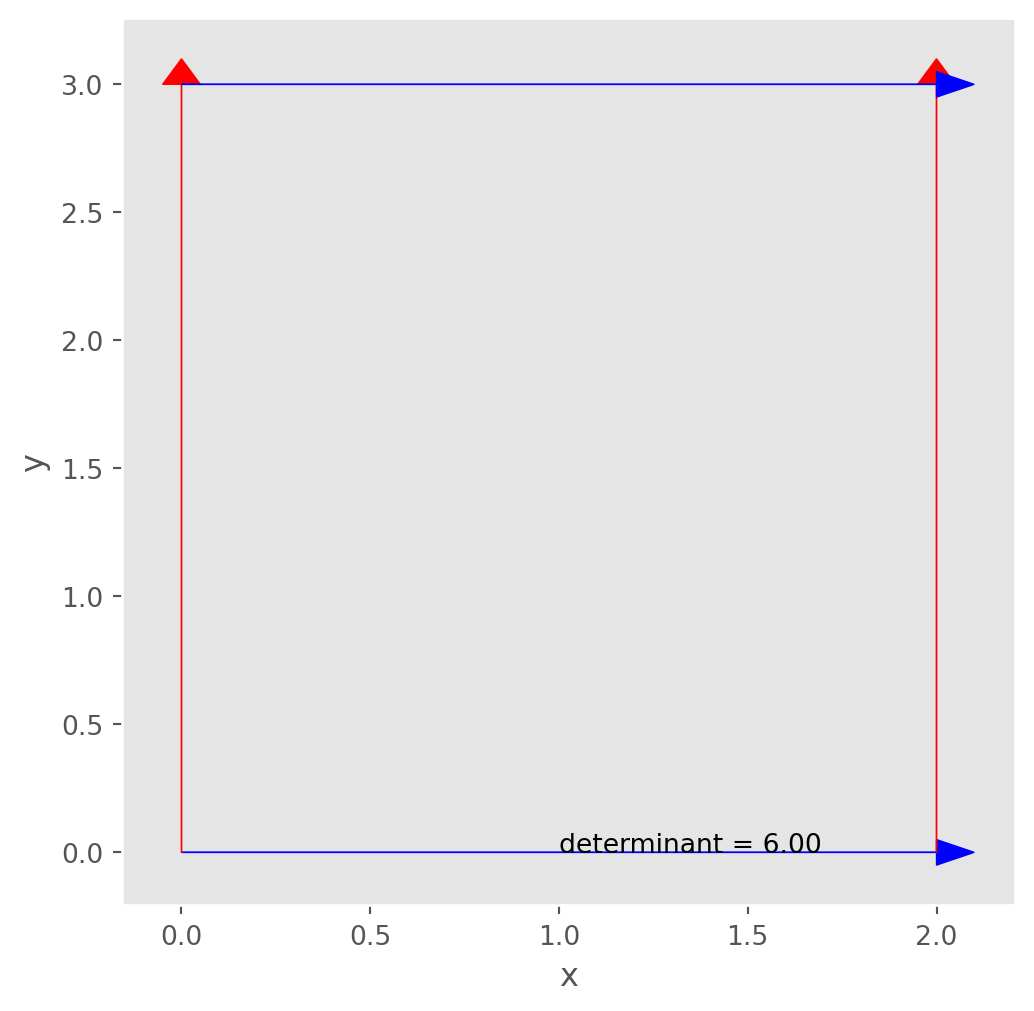
If the matrix is not diagonal, the area will take the form of a parallelogram. Similarly, in 3D space, the determinant is the volume of a parallelepiped. First let’s draw a parallelogram.
matrix = np.array([[2, 3], [1, 3]])
plot_2ddet(matrix)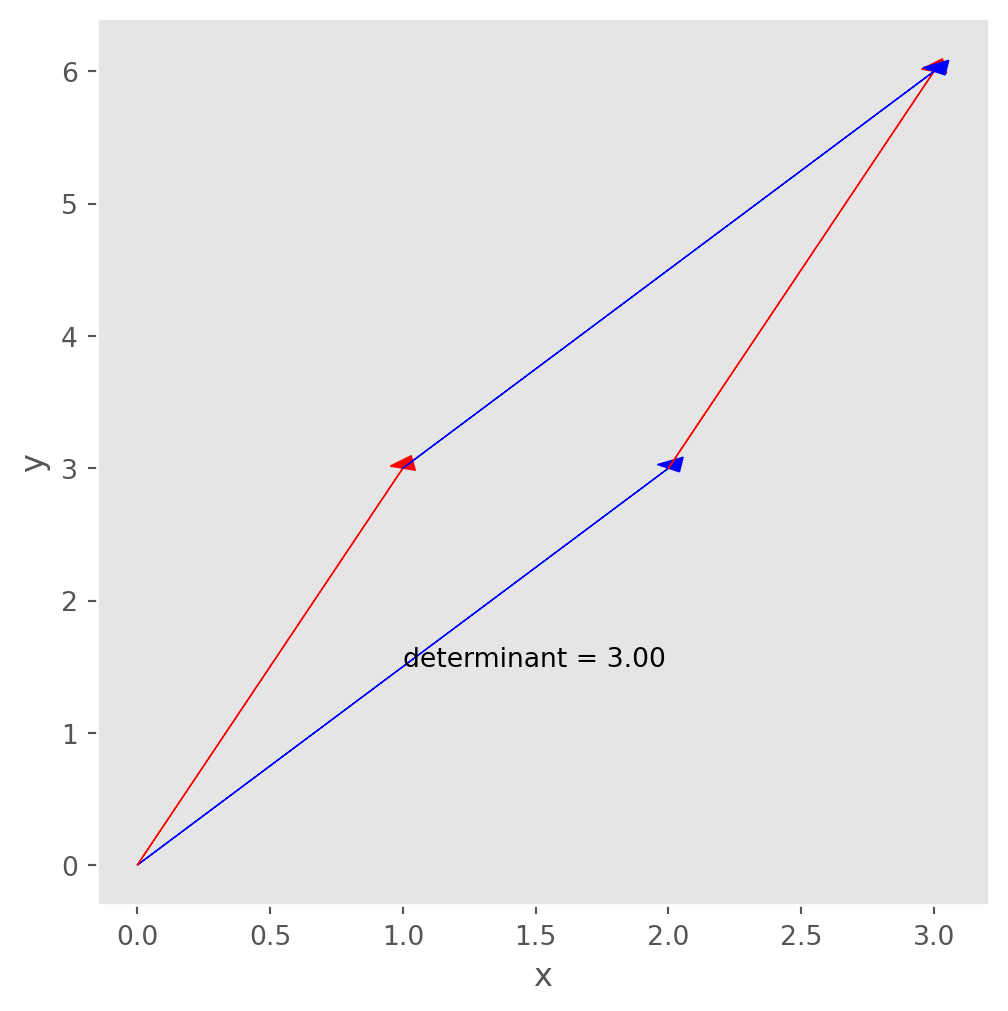
However, determinant can be a negative number, it means we flip the area like flipping a piece of paper.
What if two vectors are linearly dependent? The area between vectors will be zero.
matrix = np.array([[2, 3], [4, 6]])
plot_2ddet(matrix)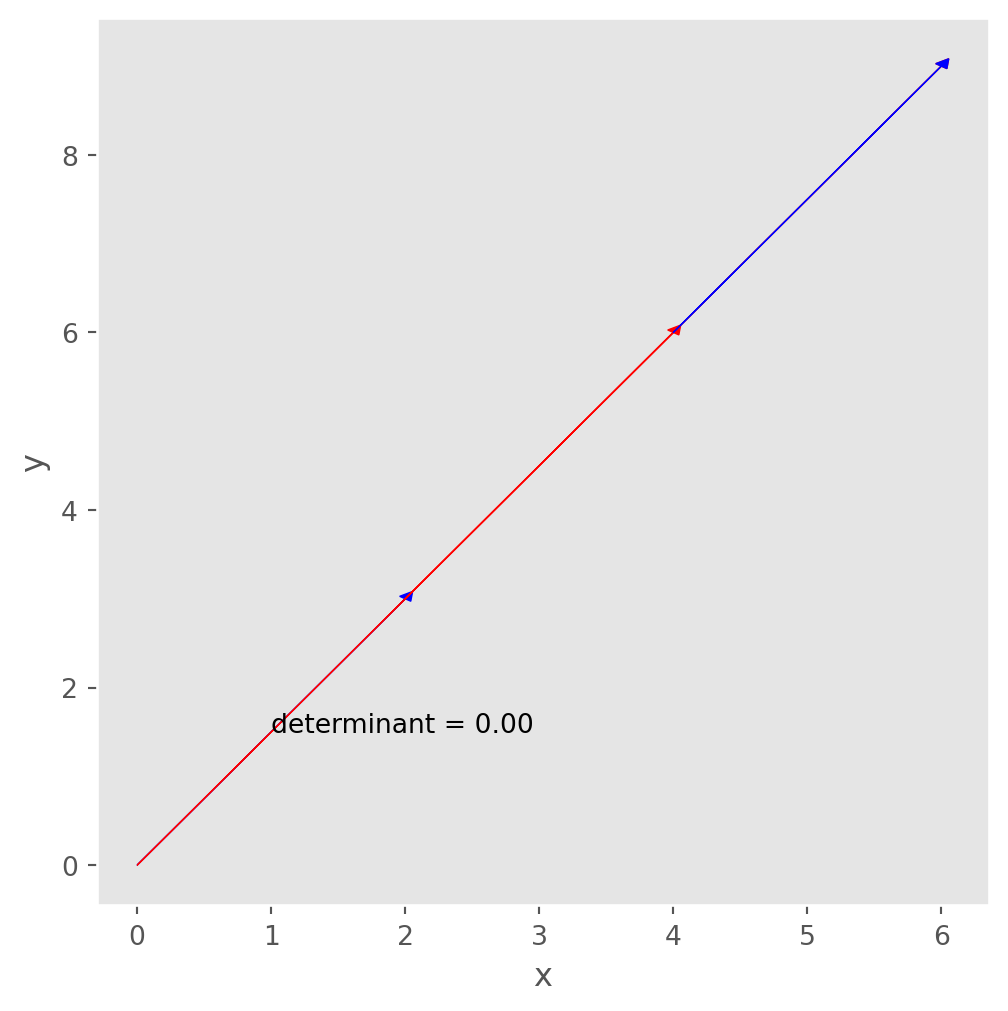
This is the exact reason if we want a matrix to have full rank or linear independent columns, the determinant can’t equal to zero!
Here’s a plot of parallelepiped, in case you are not sure how it looks.
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(8, 8))
ax = fig.add_subplot(111, projection="3d")
# Define the vertices of the parallelepiped
vertices = np.array(
[
[2, 0, 0],
[2, 3, 0],
[0, 3, 0],
[0, 0, 0],
[2, 3, 4],
[2, 6, 4],
[0, 6, 4],
[0, 3, 4],
]
)
# Plot edges between corresponding vertices
def plot_edges(vertices, pairs, color):
for i, j in pairs:
ax.plot(
[vertices[i, 0], vertices[j, 0]],
[vertices[i, 1], vertices[j, 1]],
[vertices[i, 2], vertices[j, 2]],
color=color,
)
# Pairs of indices representing edges to be plotted
bottom_edges = [(i, (i + 1) % 4) for i in range(4)]
top_edges = [(i + 4, (i + 1) % 4 + 4) for i in range(4)]
vertical_edges = [(i, i + 4) for i in range(4)]
# Plot all edges
plot_edges(vertices, bottom_edges, "blue")
plot_edges(vertices, top_edges, "k")
plot_edges(vertices, vertical_edges, "red")
# Add annotations for the coordinates at each vertex
for vertex in vertices:
ax.text(vertex[0], vertex[1], vertex[2], f"({vertex[0]}, {vertex[1]}, {vertex[2]})")
plt.show()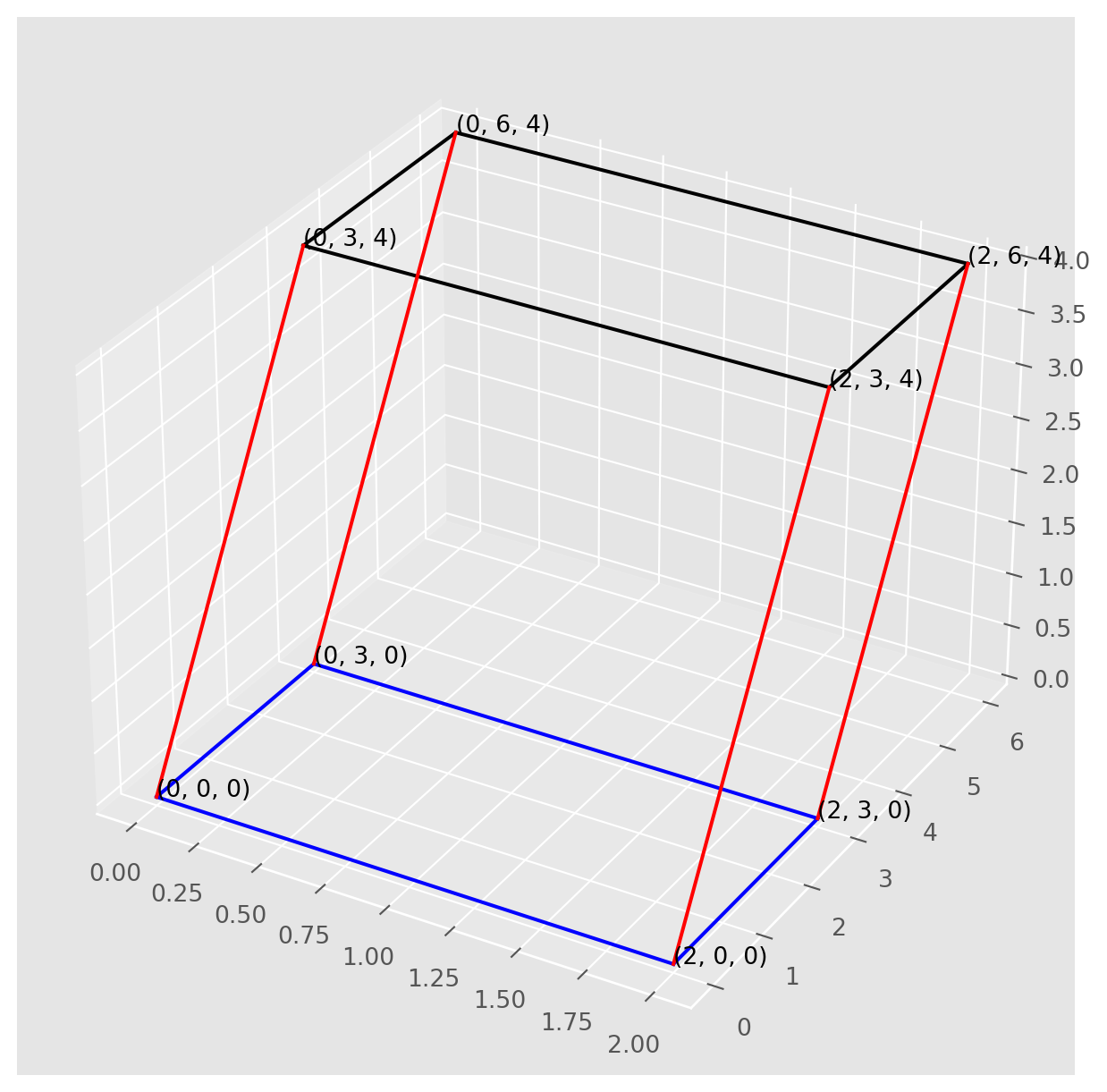
Computation of Determinants
For \(2\times 2\) matrix \(A\), the algorithm of determinant is \[ A=\left|\begin{matrix} a & b\cr c & d \end{matrix}\right| \qquad\text{is equivalent to}\qquad \text{det} A=ad-bc \]
Now we experiment with SymPy
a, b, c, d, e, f, g, h, i = sy.symbols("a, b, c, d, e, f, g, h, i", real=True)With defined symbols, the algorithms of \(2\times 2\) and \(3\times 3\) determinants are
A = sy.Matrix([[a, b], [c, d]])
A.det()\(\displaystyle a d - b c\)
Anything above than \(2 \times 2\) is become more complicated
B = sy.Matrix([[a, b, c], [d, e, f], [g, h, i]])
B.det()\(\displaystyle a e i - a f h - b d i + b f g + c d h - c e g\)
Cofactor Expansion
The \((i,j)\)-cofactor of \(A\) is denoted as \(C_{ij}\) and is given by \[C_{ij} = (-1)^{i+j} \operatorname{det} A_{ij} = (-1)^{i+j} M_{ij}\] where \(M_{ij}\) is the minor determinant obtained by excluding the \(i\)-th row and \(j\)-th column.
Let’s learn from an example. Consider the matrix \(A\): \[ A = \left[\begin{array}{rrr} 1 & 5 & 0 \\ 2 & 4 & -1 \\ 0 & -2 & 0 \end{array}\right] \] Any determinant can be expanded along an arbitrary row or column. We will expand the determinant along the first row: \[ \begin{aligned} \operatorname{det} A &= 1 \cdot \operatorname{det}\left[\begin{array}{rr} 4 & -1 \\ -2 & 0 \end{array}\right] - 5 \cdot \operatorname{det}\left[\begin{array}{cc} 2 & -1 \\ 0 & 0 \end{array}\right] + 0 \cdot \operatorname{det}\left[\begin{array}{rr} 2 & 4 \\ 0 & -2 \end{array}\right] \\ &= 1 \cdot (0 - (-2)) - 5 \cdot (0 - 0) + 0 \cdot (-4 - 0) \\ &= 1 \cdot 2 - 5 \cdot 0 + 0 \cdot (-4) \\ &= 2 - 0 + 0 \\ &= 2 \end{aligned} \]
The scalars \(1\), \(5\), and \(0\) in front of each minor determinant are the elements of the first row of \(A\).
In general, the expansions across the \(i\)-th row or \(j\)-th column are: \[ \operatorname{det} A = a_{i1} C_{i1} + a_{i2} C_{i2} + \cdots + a_{in} C_{in} \] \[ \operatorname{det} A = a_{1j} C_{1j} + a_{2j} C_{2j} + \cdots + a_{nj} C_{nj} \]
A SymPy Example of Determinant Expansion
Consider the matrix below and perform a cofactor expansion
A = sy.Matrix([[49, 0, 61], [73, 22, 96], [2, 0, 32]])
A\(\displaystyle \left[\begin{matrix}49 & 0 & 61\\73 & 22 & 96\\2 & 0 & 32\end{matrix}\right]\)
Cofactor expansion with the column which has two zero(s) involves the least computation burden:
\[\operatorname{det} A = a_{12}(-1)^{1+2}C_{12}+a_{22}(-1)^{2+2}C_{22}+a_{32}(-1)^{3+2}C_{32}\]
We can use SymPy function for calculationg minors: sy.matrices.matrices.MatrixDeterminant.minor(A, i, 1). Also we define a function for cofactor expansion:
def cof_exp(matrix, c):
"""Calculate the cofactor expansion of a matrix along the c-th column."""
detA = 0
for i in range(matrix.shape[0]): # matrix.shape[0] is the total number of rows
minor_matrix = matrix.minor_submatrix(i, c)
cofactor = (-1) ** (i + c) * minor_matrix.det()
detA += matrix[i, c] * cofactor
return detAcof_exp(A, 1)\(\displaystyle 31812\)
It’s easy to verify the expansion algorithm Sympy’s determinant evaluation function.
A.det()\(\displaystyle 31812\)
Actually you can experiment with any random matrices with multiple zeros, the function below has the parameter percent=70 which means \(70\%\) of element are non-zero.
B = sy.randMatrix(r=7, min=10, max=50, percent=70)
B\(\displaystyle \left[\begin{matrix}39 & 0 & 0 & 36 & 49 & 25 & 30\\24 & 33 & 29 & 24 & 21 & 37 & 11\\0 & 0 & 20 & 0 & 19 & 37 & 0\\0 & 0 & 0 & 11 & 36 & 0 & 22\\0 & 0 & 22 & 40 & 0 & 31 & 0\\36 & 17 & 50 & 27 & 45 & 45 & 45\\41 & 36 & 12 & 45 & 0 & 17 & 24\end{matrix}\right]\)
Calculate determinants with our user-defined function
cof_exp(B, 1)\(\displaystyle 35843162464\)
Then verify the result of using determinant method .det(). We can see indeed cofactor expansion works!
B.det()\(\displaystyle 35843162464\)
Minor matrices can also be extracted by using code .minor_submatrix(), for instance, the \(M_{23}\) matrix of $ B$ is
B.minor_submatrix(1, 2)\(\displaystyle \left[\begin{matrix}39 & 0 & 36 & 49 & 25 & 30\\0 & 0 & 0 & 19 & 37 & 0\\0 & 0 & 11 & 36 & 0 & 22\\0 & 0 & 40 & 0 & 31 & 0\\36 & 17 & 27 & 45 & 45 & 45\\41 & 36 & 45 & 0 & 17 & 24\end{matrix}\right]\)
Cofactor matrix is the matrix contains all cofactors of original matrix, and function .cofactor_matrix() can easily produce this type of matrix.
\[A=\left[\begin{array}{rrr} C_{11} & C_{12} & C_{13} \\ C_{21} & C_{22} & C_{23} \\ C_{31} & C_{32} & C_{33} \end{array}\right]= \left[\begin{array}{rrr} (-1)^{1+1}M_{11} & (-1)^{1+2}M_{12} & (-1)^{1+3}M_{13} \\ (-1)^{2+1}M_{21} & (-1)^{2+2}M_{22} & (-1)^{2+3}M_{23} \\ (-1)^{3+1}M_{31} & (-1)^{3+2}M_{32} & (-1)^{3+3}M_{33} \end{array}\right] \]
A.cofactor_matrix()\(\displaystyle \left[\begin{matrix}704 & -2144 & -44\\0 & 1446 & 0\\-1342 & -251 & 1078\end{matrix}\right]\)
Triangular Matrix
If \(A\) is triangular matrix, cofactor expansion can be applied repetitively, the outcome will be a product of the elements on the principal diagonal.
\[ \operatorname{det A}_{n\times n} = \prod_{i=1}^n a_{ii} \]
where \(a_{ii}\) is the diagonal element.
Here is the proof, start with \(A\)
\[ A=\left[\begin{array}{cccc} a_{11} & a_{12} & \cdots & a_{1 n} \\ & a_{22} & \cdots & a_{2 n} \\ & & \ddots & \vdots\\ & & & a_{n n}\\ \end{array}\right] \] Cofactor expanding on the first column, the sign of \(a_{ii}\) is always positive because \((-1)^{2i}\) \[ a_{11} \cdot \left[\begin{array}{cccc} a_{22} & a_{22} & \cdots & a_{2 n} \\ & a_{33} & \cdots & a_{3 n} \\ & & \ddots & \vdots\\ & & & a_{n n} \end{array}\right] \] Continue the cofactor expansion \[ \operatorname{det} A=a_{11} a_{22} \cdot \left[\begin{array}{cccc} a_{33} & a_{34} & \cdots & a_{3n} \\ & a_{44} & \cdots & a_{4n} \\ & & \ddots & \vdots \\ & & & a_{nn} \end{array}\right] \] Iterating the expansion, eventually \[ \text { det } A=a_{11} \cdots a_{n-2, n-2} \cdot \left[\begin{array}{cc} a_{n-1, n-1} & a_{n-1, n} \\ & a_{n n} \end{array}\right]=a_{11} \cdots a_{n n} \]
Now let’s verify with a numeric example, generate a random upper triangular matrix.
A = np.round(np.random.rand(5, 5) * 100)
A_triu = np.triu(A)
A_triuarray([[93., 10., 16., 2., 13.],
[ 0., 91., 81., 36., 78.],
[ 0., 0., 65., 48., 40.],
[ 0., 0., 0., 18., 17.],
[ 0., 0., 0., 0., 36.]])Compute the determinant with np.linalg.det
np.linalg.det(A_triu)\(\displaystyle 356461560.0\)
Extract the diagonal with np.diag(), then calculate the product. We should expect the same results.
A_diag = np.diag(A_triu)
np.prod(A_diag)\(\displaystyle 356461560.0\)
Properties of Determinants
Determinants have a long list of properties, but they are mostly derived from cofactor expansion. There is no need to memorize them.
- Let \(A\) be an \(n \times n\) square matrix. If one row of \(A\) is multiplied by \(k\) to produce the matrix \(B\), then \(\text{det} B = k \, \text{det} A\).
- Let \(A\) be an \(n \times n\) square matrix. If two rows of \(A\) are interchanged to produce a matrix \(B\), then \(\text{det} B = -\text{det} A\).
- Let \(A\) be an \(n \times n\) square matrix. If a multiple of one row of \(A\) is added to another row to produce the matrix \(B\), then \(\text{det} A = \text{det} B\).
- If \(A\) is an \(n \times n\) matrix, then \(\text{det} A^T = \text{det} A\).
- A square matrix \(A\) is invertible if and only if \(\text{det} A \neq 0\).
- If \(A\) and \(B\) are \(n \times n\) matrices, then \(\text{det} AB = (\text{det} A)(\text{det} B)\).
- If \(A\) is an \(n \times n\) matrix and \(k\) is a scalar, then \(\text{det} \, kA = k^n \, \text{det} A\).
- If \(A\) is an invertible square matrix, then \(\text{det} A^{-1} = \frac{1}{\text{det} A}\).
All of these properties are straightforward. The key is to demonstrate them using cofactor expansion. Here are some casual proofs.
Proof of property 6: \[\begin{aligned} |A B| &=\left|E_{p} \cdots E_{1} B\right|=\left|E_{p}\right|\left|E_{p-1} \cdots E_{1} B\right|=\cdots \\ &=\left|E_{p}\right| \cdots\left|E_{1}\right||B|=\cdots=\left|E_{p} \cdots E_{1}\right||B| \\ &=|A||B| \end{aligned}\]
Proof of property 7:
Because \(\text{det} B = k\, \text{det} A\), one row of \(A\) is multiplied by \(k\) to produce \(B\).Then multiply all the rows of \(A\) by \(k\), there will be \(n\) \(k\)’s in front of \(\text{det} A\), which is \(k^n \text{det} A\)
Proof of property 8: \[\begin{aligned} &\begin{aligned} A A^{-1} &=I \\ \left|A A^{-1}\right| &=|I| \end{aligned}\\ &|A|\left|A^{-1}\right|=1\\ &\left|A^{-1}\right|=\frac{1}{|A|} \end{aligned}\]
These properties are useful in the analytical derivation of other theorems; however, they are not efficient for numerical computation.
Cramer’s Rule
If a linear system has \(n\) equations and \(n\) variables, an algorithm called Cramer’s Rule can solve the system in terms of determinants as long as the solution is unique. \[ A_{n\times n}\mathbf{b}_{n} = \mathbf{x}_n \]
Some convenient notations are introduced here:
For any \(A_{n\times n}\) and vector \(\mathbf{b}\), denote \(A_i(\mathbf{b})\) as the matrix obtained from replacing the \(i\)th column of \(A\) by \(\mathbf{b}\).
\[A_{i}(\mathbf{b})=\left[\begin{array}{lllll} \mathbf{a}_{1} & \cdots & \mathbf{b} & \cdots & \mathbf{a}_{n} \end{array}\right]\]
The Cramer’s Rule can solve each \(x_i\) without solving the whole system \[x_{i}=\frac{\operatorname{det} A_{i}(\mathbf{b})}{\operatorname{det} A}, \quad i=1,2, \ldots, n\]
Fast Proof of Cramer’s Rule:
\[\begin{aligned} A \cdot I_{i}(\mathbf{x}) &=A\left[\mathbf{e}_{1} \quad \cdots \quad \mathbf{x} \quad \cdots \quad \mathbf{e}_{n}\right]=\left[\begin{array}{llllll} A \mathbf{e}_{1} & \cdots & A \mathbf{x} & \cdots & A \mathbf{e}_{n} \end{array}\right] \\ &=\left[\begin{array}{llllll} \mathbf{a}_{1} & \cdots & \mathbf{b} & \cdots & \mathbf{a}_{n} \end{array}\right]=A_{i}(\mathbf{b}) \end{aligned}\]
where \(I_i(\mathbf{x})\) is an identity matrix whose \(i\)-th column replaced by \(\mathbf{x}\). With determinant’s property, \[(\operatorname{det} A)\left(\operatorname{det} I_{i}(\mathbf{x})\right)=\operatorname{det} A_{i}(\mathbf{b})\]
\(\text{det}I_{i}(\mathbf{x})=x_i\), can be shown by cofactor expansion.
A NumPy Example On Cramer’s Rule
Consider the system \[\begin{aligned} &2 x-y+3 z=-3\\ &3 x+3 y-z=10\\ &-x-y+z=-4 \end{aligned}\]
You have surely known several ways to solve it, but let’s test if Cramer’s rule works.
Input the matrices into NumPy arrays.
A = np.array([[2, -1, 3], [3, 3, -1], [-1, -1, 1]])
b = np.array([-3, 10, -4])A_1b = np.copy(A) # Python variable is a reference tag
A_1b[:, 0] = b
A_2b = np.copy(A)
A_2b[:, 1] = b
A_3b = np.copy(A)
A_3b[:, 2] = bAccording to Cramer’s rule:
x1 = np.linalg.det(A_1b) / np.linalg.det(A)
x2 = np.linalg.det(A_2b) / np.linalg.det(A)
x3 = np.linalg.det(A_3b) / np.linalg.det(A)
(x1, x2, x3)\(\displaystyle \left( 1.0, \ 2.0, \ -1.0\right)\)
We can verify the results by NumPy built-in function np.linalg.solve.
np.linalg.solve(A, b)array([ 1., 2., -1.])Or in a straightforward way \(A^{-1}b\)
np.linalg.inv(A) @ barray([ 1., 2., -1.])All results are the same!
However, remember that Cramer’s rule is rarely used in practice for solving systems of equations, as its computational cost (measured by the number of floating-point operations, or flops) is much higher than that of Gaussian-Jordan elimination.
A Determinant Formula For Inverse Matrix
An alternative algorithm for \(A^{-1}\) is \[A^{-1}=\frac{1}{\operatorname{det} A}\left[\begin{array}{cccc} C_{11} & C_{21} & \cdots & C_{n 1} \\ C_{12} & C_{22} & \cdots & C_{n 2} \\ \vdots & \vdots & & \vdots \\ C_{1 n} & C_{2 n} & \cdots & C_{n n} \end{array}\right]\]
where the matrix of cofactors on RHS is the adjugate matrix, SymPy function is sy.matrices.matrices.MatrixDeterminant.adjugate. And this is the transpose of the cofactor matrix which we computed using sy.matrices.matrices.MatrixDeterminant.cofactor_matrix
A SymPy Example
Generate a random matrix with \(20\%\) of zero elements.
A = sy.randMatrix(5, min=-5, max=5, percent=80)
A\(\displaystyle \left[\begin{matrix}0 & -5 & -3 & 3 & 0\\-2 & 2 & 1 & 1 & -1\\-5 & 2 & -3 & 4 & 4\\-2 & -5 & -4 & 4 & -3\\0 & 0 & -5 & -4 & 0\end{matrix}\right]\)
Compute the adjugate matrix
A_adjugate = A.adjugate()
A_adjugate\(\displaystyle \left[\begin{matrix}726 & 822 & -132 & -450 & 168\\573 & 621 & -108 & -351 & 126\\-412 & -460 & 80 & 260 & -84\\515 & 575 & -100 & -325 & 126\\-203 & -203 & 28 & 133 & -42\end{matrix}\right]\)
We can verify if this really the adjugate of \(A\), we pick element of \((1, 3), (2, 4), (5, 4)\) of \(A\) to compute the cofactors
display(
f"(2, 0) minor: {(-1)**(1+3) * A.minor(2, 0)}"
) # (1, 3) cofactor of A, transposed index
display(f"(3, 1) minor: {(-1)**(2+4) * A.minor(3, 1)}")
display(f"(3, 4) minor: {(-1)**(5+4) * A.minor(3, 4)}")'(2, 0) minor: -132''(3, 1) minor: -351''(3, 4) minor: 133'Adjugate is the transpose of cofactor matrix, thus we reverse the row and column index when referring to the elements. As we have shown it is truel adjugate matrix.
Next we will check if this inverse formula works with SymPy’s function.
The sy.N() is for converting to float approximation, i.e. if you don’t like fractions.
A_det = A.det()
A_inv = (1 / A_det) * A_adjugate
round_expr(sy.N(A_inv), 4)\(\displaystyle \left[\begin{matrix}-8.6429 & -9.7857 & 1.5714 & 5.3571 & -2.0\\-6.8214 & -7.3929 & 1.2857 & 4.1786 & -1.5\\4.9048 & 5.4762 & -0.9524 & -3.0952 & 1.0\\-6.131 & -6.8452 & 1.1905 & 3.869 & -1.5\\2.4167 & 2.4167 & -0.3333 & -1.5833 & 0.5\end{matrix}\right]\)
Now again, we can verify the results with .inv()
round_expr(sy.N(A.inv()), 4)\(\displaystyle \left[\begin{matrix}-8.6429 & -9.7857 & 1.5714 & 5.3571 & -2.0\\-6.8214 & -7.3929 & 1.2857 & 4.1786 & -1.5\\4.9048 & 5.4762 & -0.9524 & -3.0952 & 1.0\\-6.131 & -6.8452 & 1.1905 & 3.869 & -1.5\\2.4167 & 2.4167 & -0.3333 & -1.5833 & 0.5\end{matrix}\right]\)
Or We can show by difference.
A_inv - A.inv()\(\displaystyle \left[\begin{matrix}0 & 0 & 0 & 0 & 0\\0 & 0 & 0 & 0 & 0\\0 & 0 & 0 & 0 & 0\\0 & 0 & 0 & 0 & 0\\0 & 0 & 0 & 0 & 0\end{matrix}\right]\)
So Cramer’s rule indeed works perfectly.
Short Proof of \(A^{-1}\) Formula With Determinants
We define \(x\) the \(j\)-th column of \(A^{-1}\) which satisfies \[ Ax= e_j \]
and \(e_j\) is the \(j\)-th column of an identity matrix, and \(j\)th entry of \(x\) is the \((i,j)\)-entry of \(A^{-1}\). By Cramer’s rule,
\[\left\{(i, j) \text { -entry of } A^{-1}\right\}=x_{i}=\frac{\operatorname{det} A_{i}\left(\mathbf{e}_{j}\right)}{\operatorname{det} A}\]
The cofactor expansion along column \(i\) of \(A_i(e_j)\), \[\operatorname{det} A_{i}\left(\mathbf{e}_{j}\right)=(-1)^{i+j} \operatorname{det} A_{j i}=C_{j i}\]