import yfinance as yfimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.decomposition import PCAimport datetime as dt# Fetch bond yield data from Yahoo Financetickers = ["^IRX","^FVX","^TNX","^TYX",] # 13-week, 5-year, 10-year, 30-year treasury yield indicesdata = yf.download(tickers, start="2010-01-01", end=dt.datetime.today())["Adj Close"]# Display the first few rows of the datasetdata.head()
[ 0% ][**********************50% ] 2 of 4 completed[**********************75%*********** ] 3 of 4 completed[*********************100%***********************] 4 of 4 completed
Ticker
^FVX
^IRX
^TNX
^TYX
Date
2010-01-04 00:00:00+00:00
2.652
0.055
3.841
4.660
2010-01-05 00:00:00+00:00
2.558
0.060
3.755
4.593
2010-01-06 00:00:00+00:00
2.573
0.045
3.808
4.671
2010-01-07 00:00:00+00:00
2.600
0.045
3.822
4.689
2010-01-08 00:00:00+00:00
2.566
0.040
3.808
4.695
data\(A\) is the feature data set, the columns are features with various terms of bonds. The matrices \(A A^T\) and \(A^T A\) share the same nonzero eigenvalues. This proposition is very powerful in the case that \(m\) and \(n\) are drastically different in size. For instance, if \(A\) is \(1000 × 4\), then there’s a quick way to find the eigenvalues of the \(1000 × 1000\) matrix \(AA^T\), first find the eigenvalues of \(A^TA\) (which is only 4 × 4). The other \(996\) eigenvalues of \(AA^T\) are all zero!
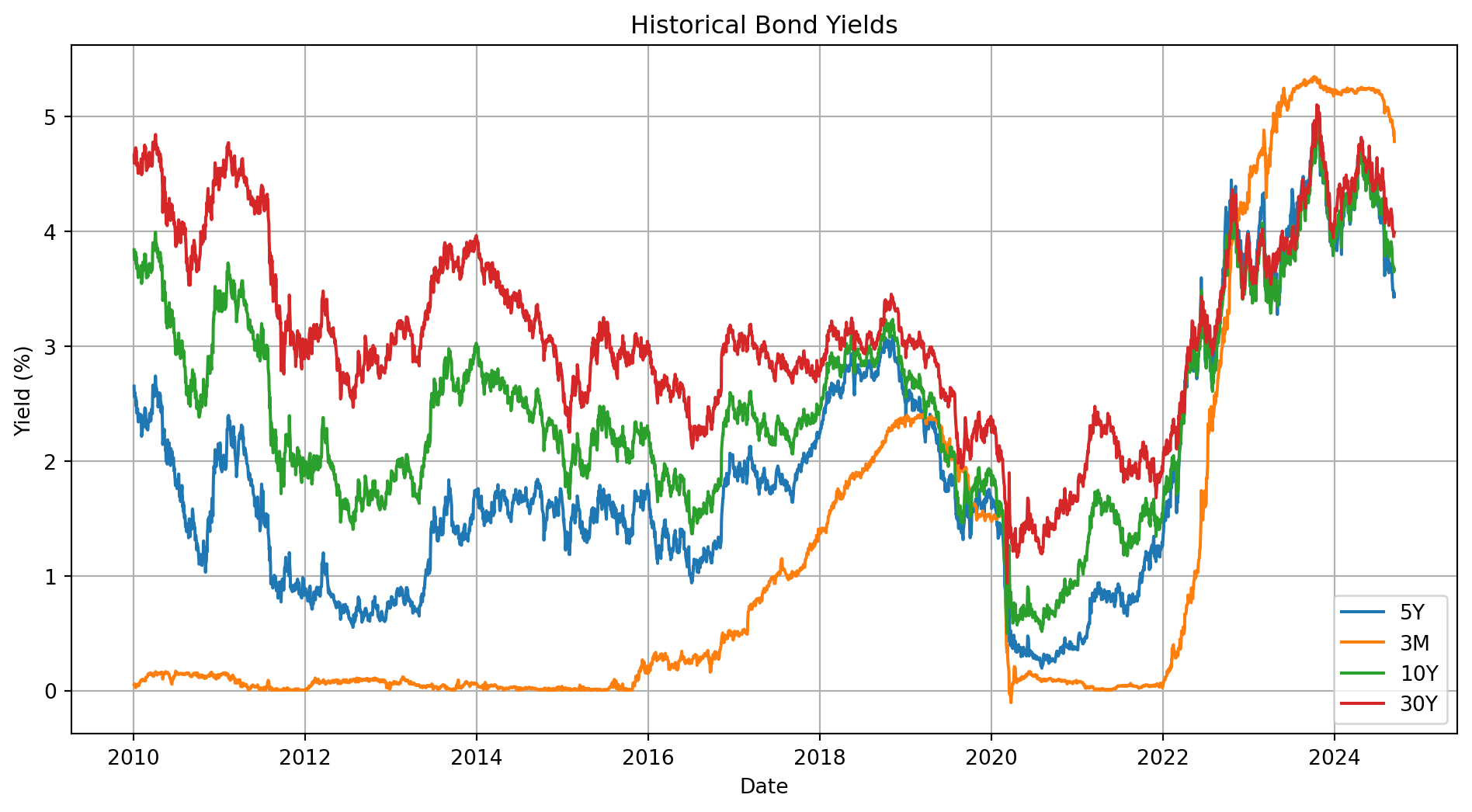
# Handle missing values by forward fillingdata = data.rename(columns={"^IRX": "3M", "^FVX": "5Y", "^TNX": "10Y", "^TYX": "30Y"})data = data.ffill()# Check for any remaining missing valuesprint(f"Missiong data counts {data.isnull().sum()}")# Plot the bond yieldsplt.figure(figsize=(12, 6))for column in data.columns: plt.plot(data.index, data[column], label=column)plt.xlabel("Date")plt.ylabel("Yield (%)")plt.title("Historical Bond Yields")plt.legend()plt.grid(True)plt.show()
We need to normalize the data, this makes sure that data with different unit or scale do not dominate.Eigenvalues and eigenvectors of the covariance matrix are used to determine the principal components in PCA.The eigenvectors provide the directions of the new feature space, and the eigenvalues indicate the importance of each direction.
# Standardize the data (mean = 0, variance = 1)data_standardized = (data - data.mean()) / data.std()
Covariance matrix is diagonalized (specifically spectral decomposition as we discuss in chapter of Diagonalization) \[
C = V \Lambda V^T
\]
Apply the theorem, and let $ _1 _2 _m $ be the eigenvalues of \(C\) with corresponding eigenvectors \(v_1, v_2, ..., v_m\).
These eigenvectors are the principal component of the data.
data_cov = data_standardized.cov()data_cov
Ticker
5Y
3M
10Y
30Y
Ticker
5Y
1.000000
0.884855
0.907693
0.670862
3M
0.884855
1.000000
0.700006
0.436464
10Y
0.907693
0.700006
1.000000
0.916354
30Y
0.670862
0.436464
0.916354
1.000000
data_corr = data_standardized.corr()data_corr
Ticker
5Y
3M
10Y
30Y
Ticker
5Y
1.000000
0.884855
0.907693
0.670862
3M
0.884855
1.000000
0.700006
0.436464
10Y
0.907693
0.700006
1.000000
0.916354
30Y
0.670862
0.436464
0.916354
1.000000
eig = np.linalg.eig(data_cov)eigenvalues = eig[0]eigenvectors = eig[1] # eigenvectors are not principal components, they are the directions of the principal components
A fact we will need now: the sum of the eigenvalues is the trace of a symmetric matrix. It can be simply proved \[
\operatorname{tr}(C)=\operatorname{tr}\left(P \Lambda P^{-1}\right)=\operatorname{tr}\left(P^{-1} P \Lambda\right)=\operatorname{tr}(\Lambda)
\] which used cyclic property of trace.
The trace of covariance matrix is the sum of variances, let’s compute it.
np.trace(data_cov)
4.0
It wouldn’t surprise you, the trace equal \(m\), the number of features, because we have already normalized every feature, so the variance is \(1\) for each feature, and the sum of variances will be the number of features, i.e. \[
\text{Tr}(C) = m
\] But also we have proved, the sum of eigenvalues should equal to the trace of a symmetric matrix, in our case a covariance matrix. Let’s see if this is true.
np.sum(eigenvalues)
4.000000000000003
Though a bit rounding errors in computation, the sum of eigenvalues should be equal to \(m\) or sum of variances.
So the each principle accounts a percentage of total variance \[
\frac{\lambda_i}{Tr(C)}
\]
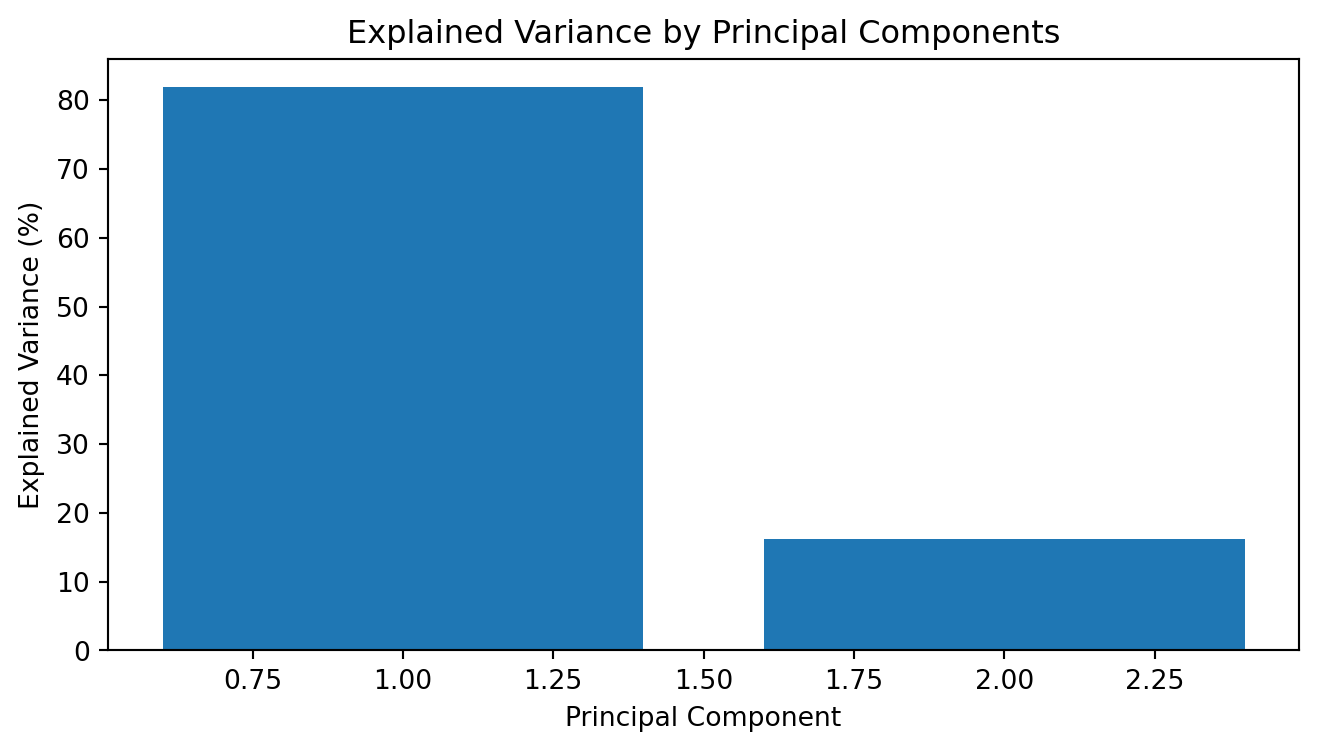
We can show the cumulative sum of ratio, the first two principal account for \(98\%\) of variances, we can reduce the data’s dimensionality to two dimensions (using only the first two principal components) while preserving most of the information (variance).
(eigenvalues / np.trace(data_cov)).cumsum()
array([0.81891178, 0.98068124, 0.99957395, 1. ])
Therefore we can reduce the orginal data’s dimension by projecting original data onto principal components. This transformation creates a new dataset.
The transformation process is done by multiplying original data \(A\) by matrix of eigenvectors \(V\)
\[
Y = A V
\]
Now let’s use sklearn library to perform the computation.
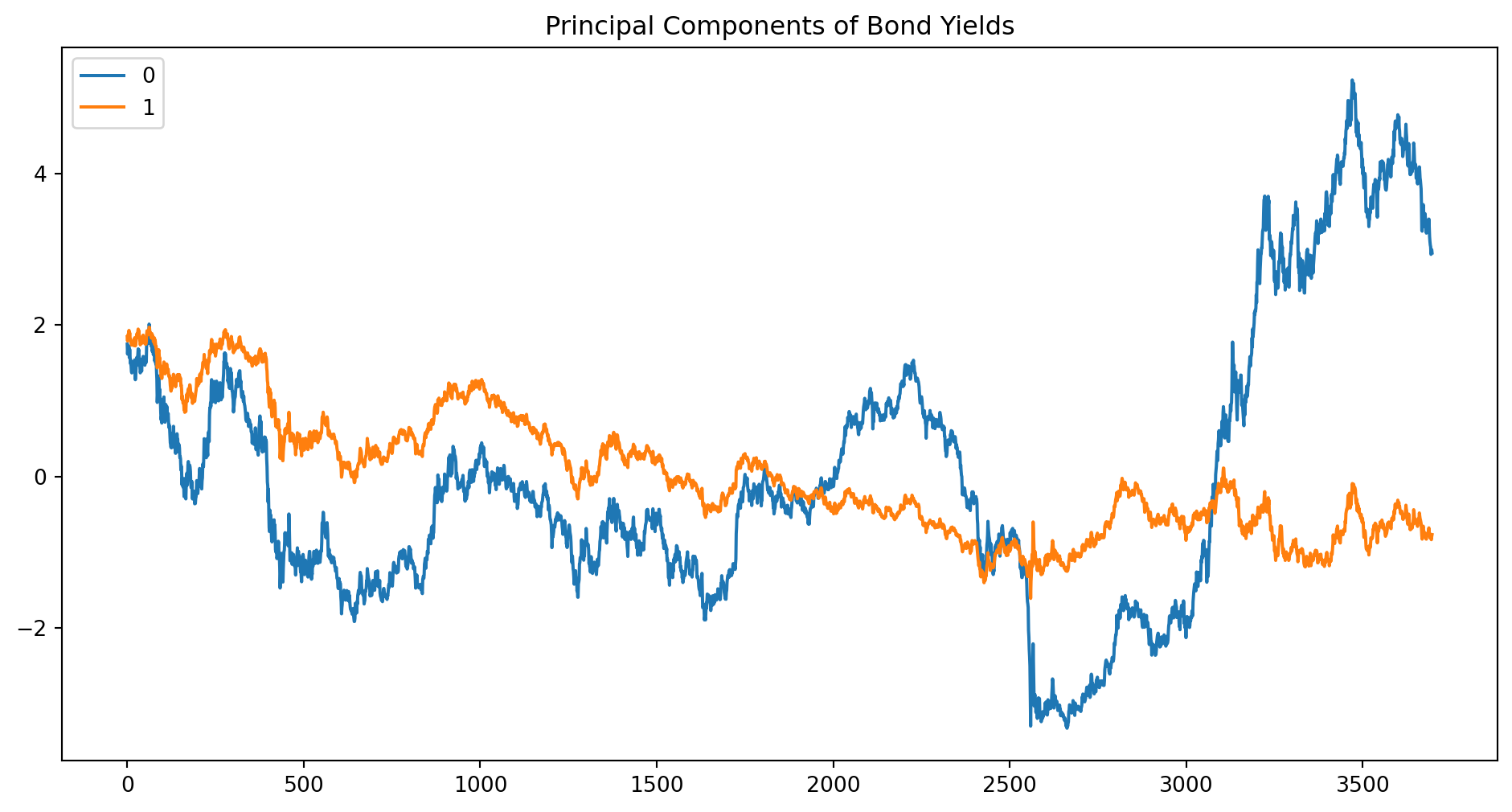
# Perform PCApca = PCA(n_components=2) # We only first two dominating principal componentsprincipal_components = pca.fit_transform(data_standardized)
pd.DataFrame(principal_components).plot( figsize=(12, 6), title="Principal Components of Bond Yields")
# Explained variance by each principal componentexplained_variance = pca.explained_variance_ratio_# Print explained varianceprint("Explained Variance by Each Principal Component:")for i, variance inenumerate(explained_variance):print(f"Principal Component {i+1}: {variance:.2%}")# Create a DataFrame with principal componentspc_df = pd.DataFrame( data=principal_components, columns=[f"PC{i+1}"for i inrange(explained_variance.size)],)
Explained Variance by Each Principal Component:
Principal Component 1: 81.89%
Principal Component 2: 16.18%
pc_df
PC1
PC2
0
1.747698
1.844953
1
1.615660
1.788682
2
1.693399
1.867529
3
1.724687
1.879223
4
1.701948
1.890274
...
...
...
3692
3.031716
-0.809538
3693
2.932136
-0.820956
3694
2.960896
-0.832832
3695
2.994151
-0.790869
3696
2.950948
-0.765678
3697 rows × 2 columns
PCA Loadings
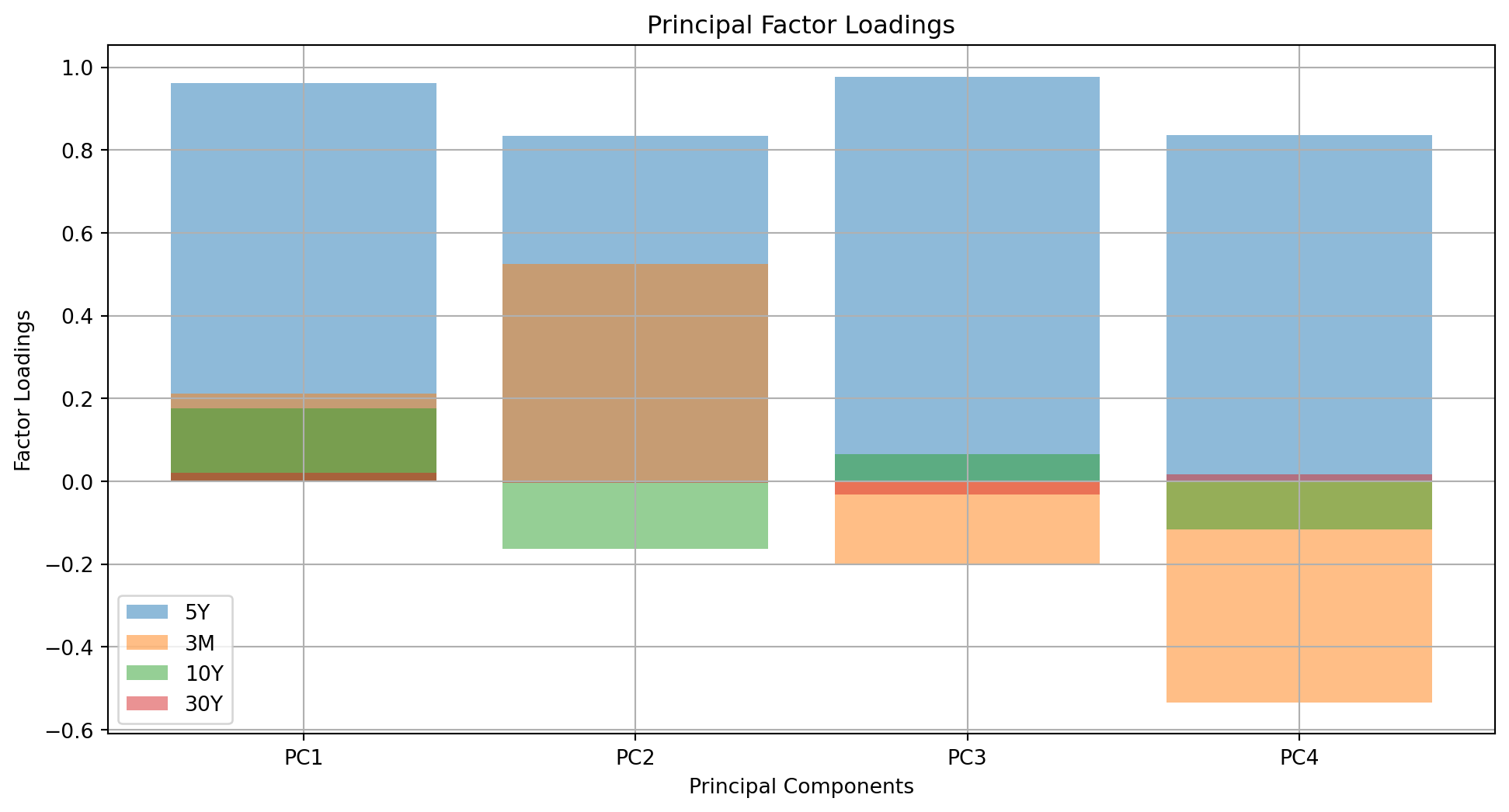
We need to define PCA factor loadings before further analysis. \[
L = \sqrt{\Lambda}V
\] where \(\Lambda\) and \(V\) are diagonal matrix with eigenvalue and matrix of eigenvector accordingly. The factoring are scaled version of matrix of eigenvectors. It represents the contribution of each original variable to the principal components. They are scaled versions of the eigenvectors, making them more interpretable in terms of the variance explained by each component.
# Plot the factor loadingsplt.figure(figsize=(12, 6))for i inrange(len(data.columns)): plt.bar(range(1, len(data.columns) +1), factor_loadings_df[:, i], alpha=0.5, align="center", label=f"{data.columns[i]}", )plt.xlabel("Principal Components")plt.ylabel("Factor Loadings")plt.title("Principal Factor Loadings")plt.xticks(range(1, len(data.columns) +1), [f"PC{i+1}"for i inrange(len(data.columns))])plt.legend(loc="best")plt.grid(True)plt.show()
# Plot explained varianceplt.figure(figsize=(8, 4))plt.bar(range(1, len(explained_variance) +1), explained_variance *100)plt.xlabel("Principal Component")plt.ylabel("Explained Variance (%)")plt.title("Explained Variance by Principal Components")plt.show()# Plot the first two principal componentsplt.figure(figsize=(12, 6))plt.scatter(pc_df["PC1"], pc_df["PC2"], c="blue", edgecolor="k", alpha=0.5)plt.xlabel("Principal Component 1")plt.ylabel("Principal Component 2")plt.title("PCA of Bond Yields")plt.grid(True)plt.show()